Astra is a Python-based system that detects structural similarity between programming assignments using AST normalization and sequence alignment.
You can read more about this project in this
notebook
Why we built it
Plagiarism in programming assignments is usually not literal copy paste. Students change variable names, reorder code, or tweak formatting while keeping the same logic. Text based comparison breaks under these cases.
Astra was built to detect similarity at the structure level instead of raw text.
How it turned out
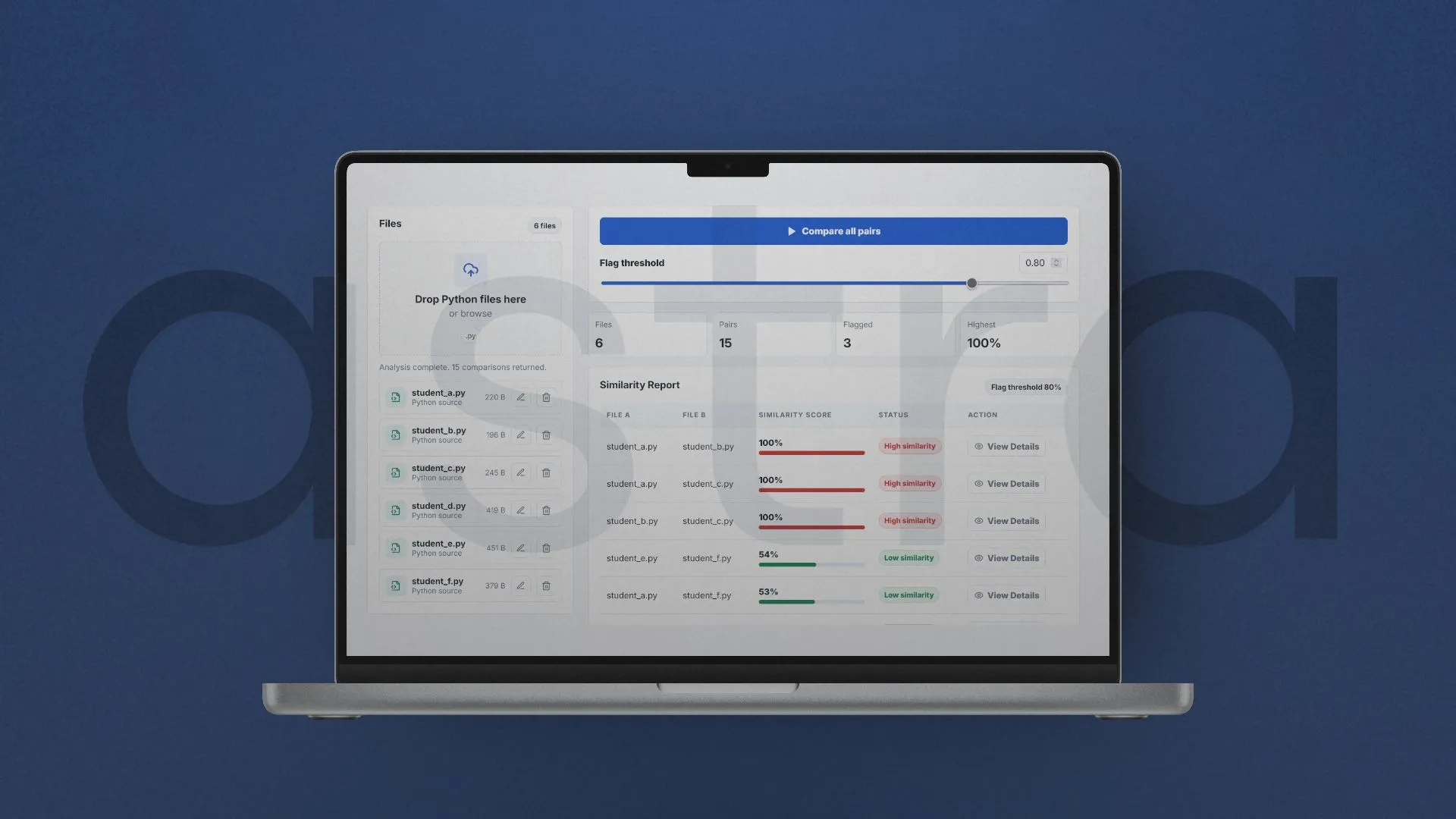
Astra can be used as a command line tool or a web app.
The CLI runs full batch analysis from a folder of Python submissions and outputs ranked similarity reports. It is the fastest way to process datasets and is mainly used for running the core pipeline end to end.
The web app exposes the same system through an interface and API, allowing results to be explored visually. It is useful for inspecting comparisons and flagged pairs in a more interactive way.
How we build it
Core idea
Instead of comparing code as text, Astra compares how the code is structured.
Each program is:
- parsed into an Abstract Syntax Tree (AST)
- normalized to remove noise like variable names and literals
- split into structural chunks like functions and classes
- converted into token sequences
- compared using sequence alignment
Chunk-based comparison
Each file is broken into independent structural units.
This allows partial plagiarism detection, function level matching, and resilience to code reordering.
Similarity scoring
Chunks are compared using edit distance.
The system uses Damerau-Levenshtein distance which allows insertions, deletions, substitutions, and transpositions.